


What is Git?
Git is a version control system that allows you to track changes to files and coordinate work on those files among multiple people. It is commonly used for software development, but it can be used to track changes to any set of files.
With Git, you can keep a record of who made changes to what part of a file, and you can revert back to earlier versions of the file if needed. Git also makes it easy to collaborate with others, as you can share changes and merge the changes made by different people into a single version of a file.
What is GitHub?
GitHub is a web-based platform that provides hosting for version control using Git. It is a subsidiary of Microsoft, and it offers all of the distributed version control and source code management (SCM) functionality of Git as well as adding its own features. GitHub is a very popular platform for developers to share and collaborate on projects, and it is also used for hosting open-source projects.
What is Version Control? How many types of version controls we have?
Version control is a system that tracks changes to a file or set of files over time so that you can recall specific versions later. It allows you to revert files back to a previous state, revert the entire project back to a previous state, compare changes over time, see who last modified something that might be causing a problem, who introduced an issue and when, and more.
There are two main types of version control systems: centralized version control systems and distributed version control systems.
A centralized version control system (CVCS) uses a central server to store all the versions of a project's files. Developers "check out" files from the central server, make changes, and then "check in" the updated files. Examples of CVCS include Subversion and Perforce.
A distributed version control system (DVCS) allows developers to "clone" an entire repository, including the entire version history of the project. This means that they have a complete local copy of the repository, including all branches and past versions. Developers can work independently and then later merge their changes back into the main repository. Examples of DVCS include Git, Mercurial, and Darcs.
Why do we use distributed version control over centralized version control?
Better collaboration: In a DVCS, every developer has a full copy of the repository, including the entire history of all changes. This makes it easier for developers to work together, as they don't have to constantly communicate with a central server to commit their changes or to see the changes made by others.
Improved speed: Because developers have a local copy of the repository, they can commit their changes and perform other version control actions faster, as they don't have to communicate with a central server.
Greater flexibility: With a DVCS, developers can work offline and commit their changes later when they do have an internet connection. They can also choose to share their changes with only a subset of the team, rather than pushing all of their changes to a central server.
Enhanced security: In a DVCS, the repository history is stored on multiple servers and computers, which makes it more resistant to data loss. If the central server in a CVCS goes down or the repository becomes corrupted, it can be difficult to recover the lost data.
Overall, the decentralized nature of a DVCS allows for greater collaboration, flexibility, and security, making it a popular choice for many teams.
Demo:
Install Git on your computer
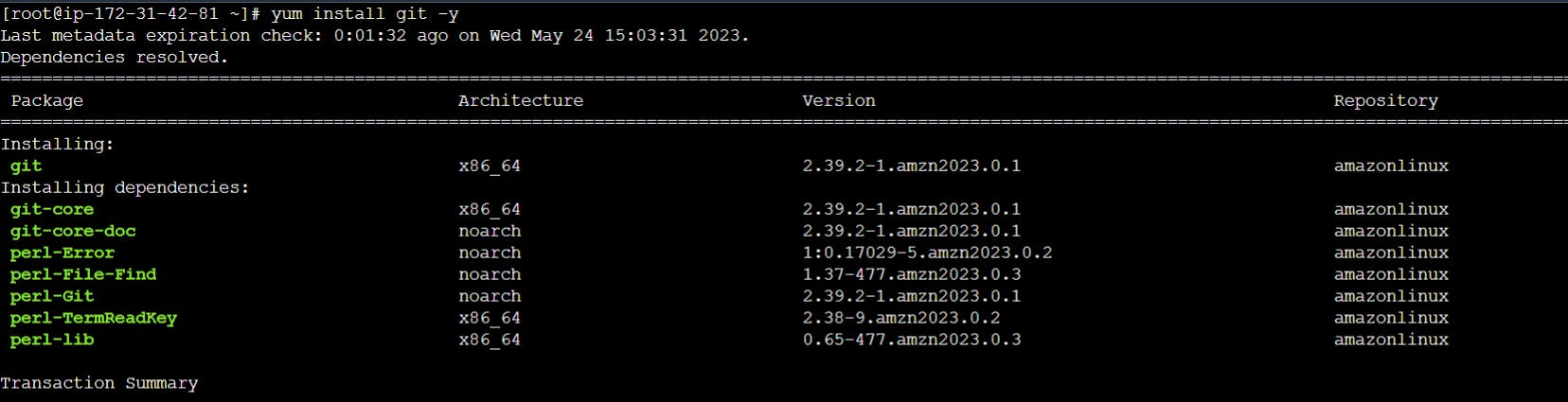
git --version
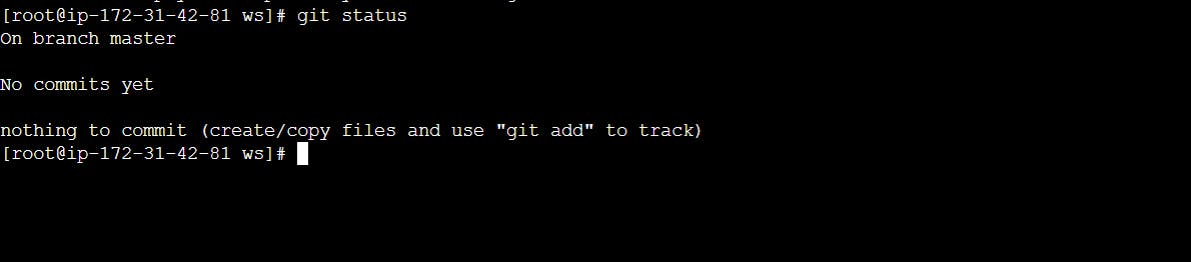
to int
to status
DESCRIPTION
This tutorial explains how to import a new project into Git, make changes to it, and share changes with other developers.
you can get documentation for a command such as git log --graph with:
$ man git-log
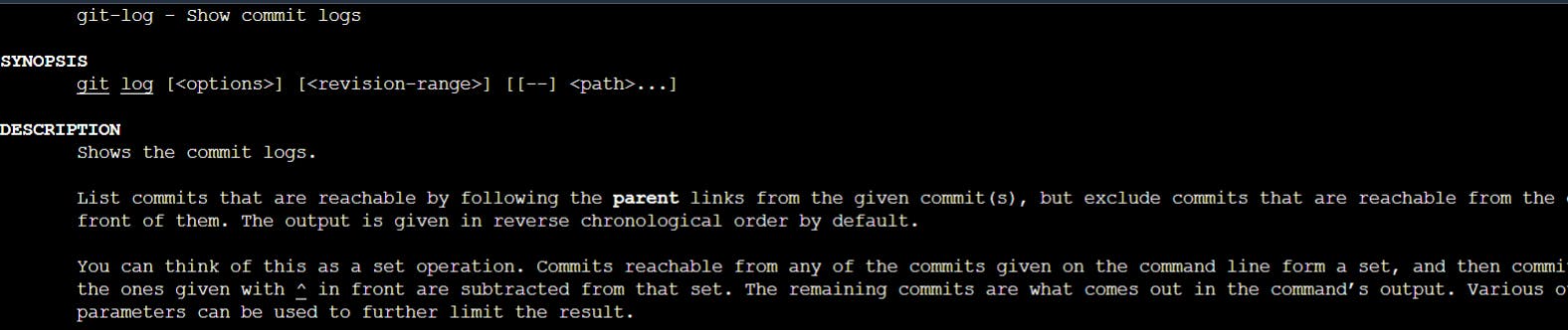
or:
$ git help log
It is a good idea to introduce yourself to Git with your name and public email address before doing any operation. The easiest way to do so is:
$ git config --global user.name "Swapnil khairnar"
$ git config --global user.email swapnilkhairnar.78@gmail.com

Importing a new project
Assume you have a tarball project.tar.gz with your initial work. You can place it under Git revision control as follows.
$ git init
$ cd project
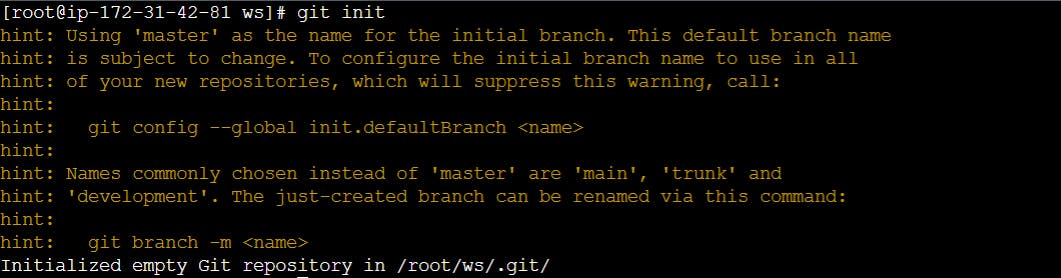
Git will reply
Initialized empty Git repository in .git/
You’ve now initialized the working directory—you may notice a new directory created, named ".git".
Next, tell Git to take a snapshot of the contents of all files under the current directory (note the .), with git add:
$ git add .
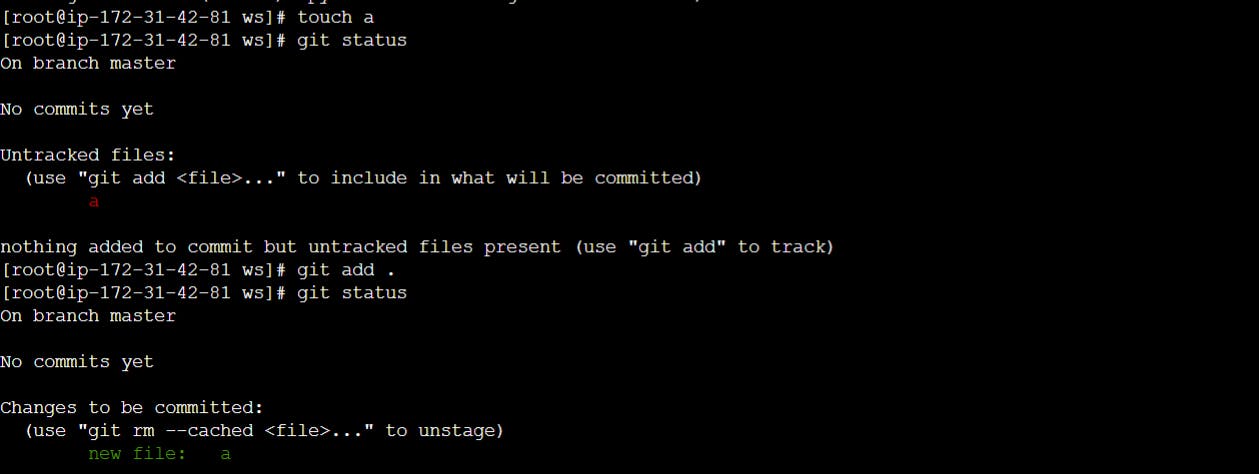
This snapshot is now stored in a temporary staging area which Git calls the "index". You can permanently store the contents of the index in the repository with git commit:
$ git commit

This will prompt you for a commit message. You’ve now stored the first version of your project in Git.
Making changes
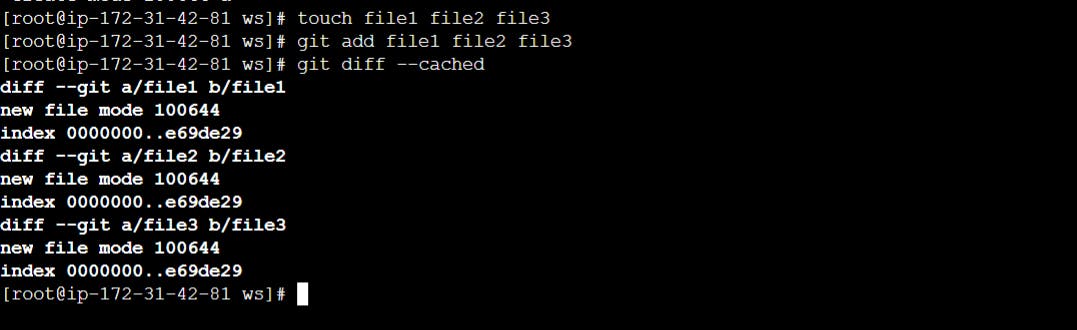
Modify some files, then add their updated contents to the index:
$ git add file1 file2 file3
You are now ready to commit. You can see what is about to be committed using git diff with the --cached option:
$ git diff --cached
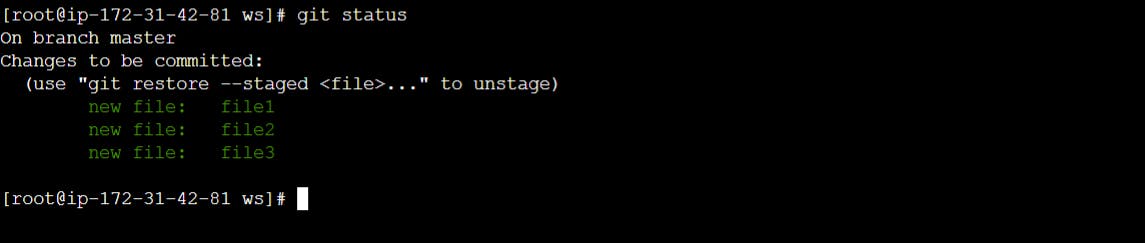
(Without --cached, git diff will show you any changes that you’ve made but not yet added to the index.) You can also get a brief summary of the situation with git status:
$ git status
On branch master
Changes to be committed:
Your branch is up to date with 'origin/master'.
(use "git restore --staged <file>..." to unstage)
modified: file1
modified: file2
modified: file3
If you need to make any further adjustments, do so now, and then add any newly modified content to the index. Finally, commit your changes with:
$ git commit
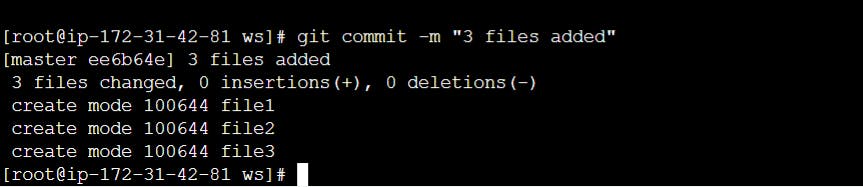
This will again prompt you for a message describing the change, and then record a new version of the project.
Alternatively, instead of running git add beforehand, you can use
$ git commit -a
which will automatically notice any modified (but not new) files, add them to the index, and commit, all in one step.
A note on commit messages: Though not required, it’s a good idea to begin the commit message with a single short (less than 50 character) line summarizing the change, followed by a blank line and then a more thorough description. The text up to the first blank line in a commit message is treated as the commit title, and that title is used throughout Git. For example, git-format-patch[1] turns a commit into email, and it uses the title on the Subject line and the rest of the commit in the body.
Git tracks content not files
Many revision control systems provide an add command that tells the system to start tracking changes to a new file. Git’s add command does something simpler and more powerful: git add is used both for new and newly modified files, and in both cases it takes a snapshot of the given files and stages that content in the index, ready for inclusion in the next commit.
Viewing project history
At any point you can view the history of your changes using
$ git log
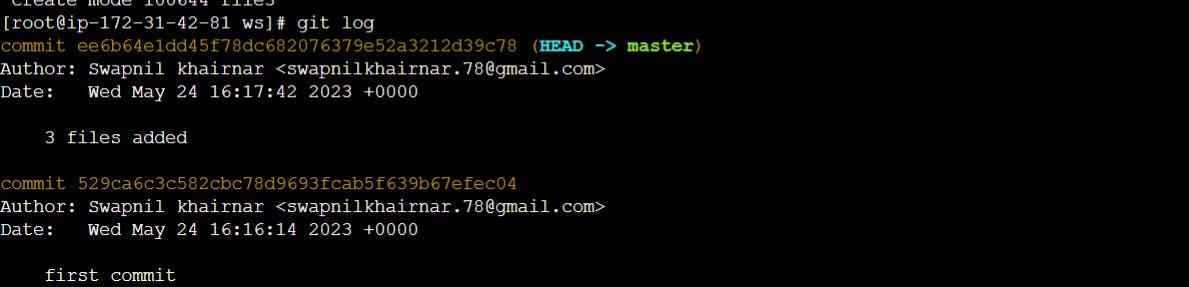
If you also want to see complete diffs at each step, use
$ git log -p
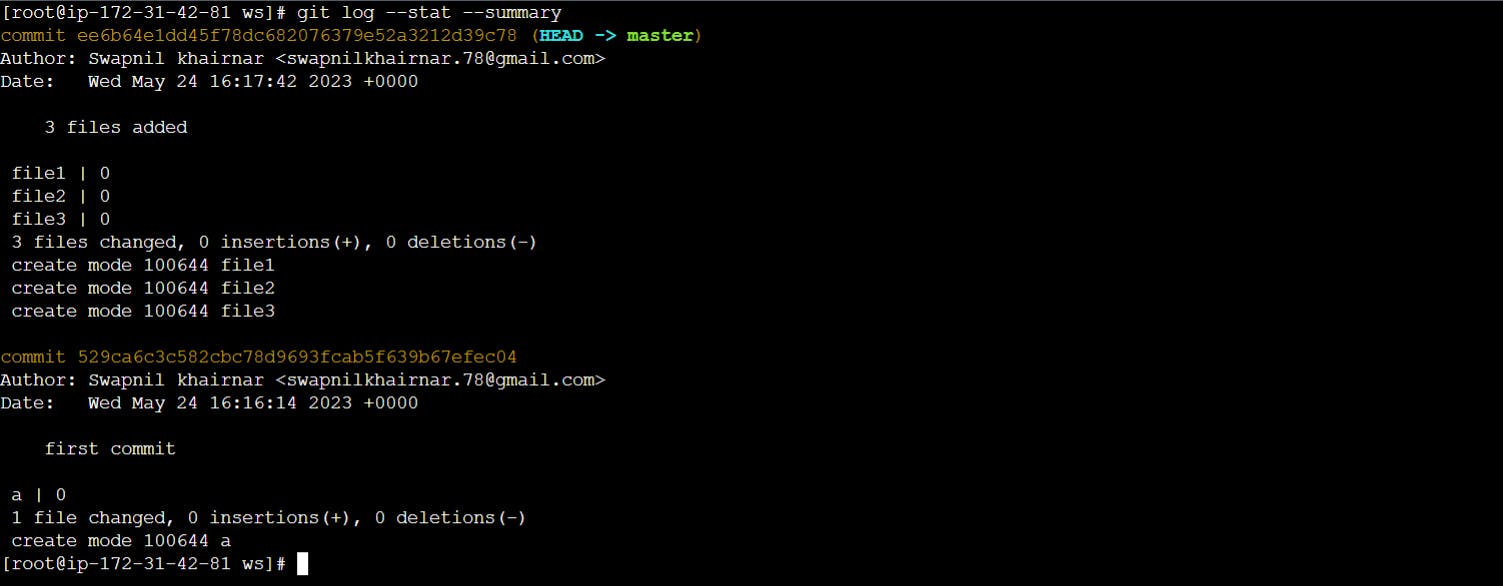
Often the overview of the change is useful to get a feel of each step
$ git log --stat --summary
Thanks for reading my article. Have a nice day.

For updates follow me on LinkedIn: Swapnil Khairnar
Hashtags:
#90daysofdevops #devops #cloud #aws #awscloud #awscommunity #docker #linux #kubernetes #k8s #ansible #grafana #terraform #github #opensource #90daysofdevops #challenge #learningprogress #freelancer #linkedin #trainwithshubham #devopscommunity #cloudproviders #bash #bashshellscripting #awkward #shellscripting